Experiments
CartPole Environment:
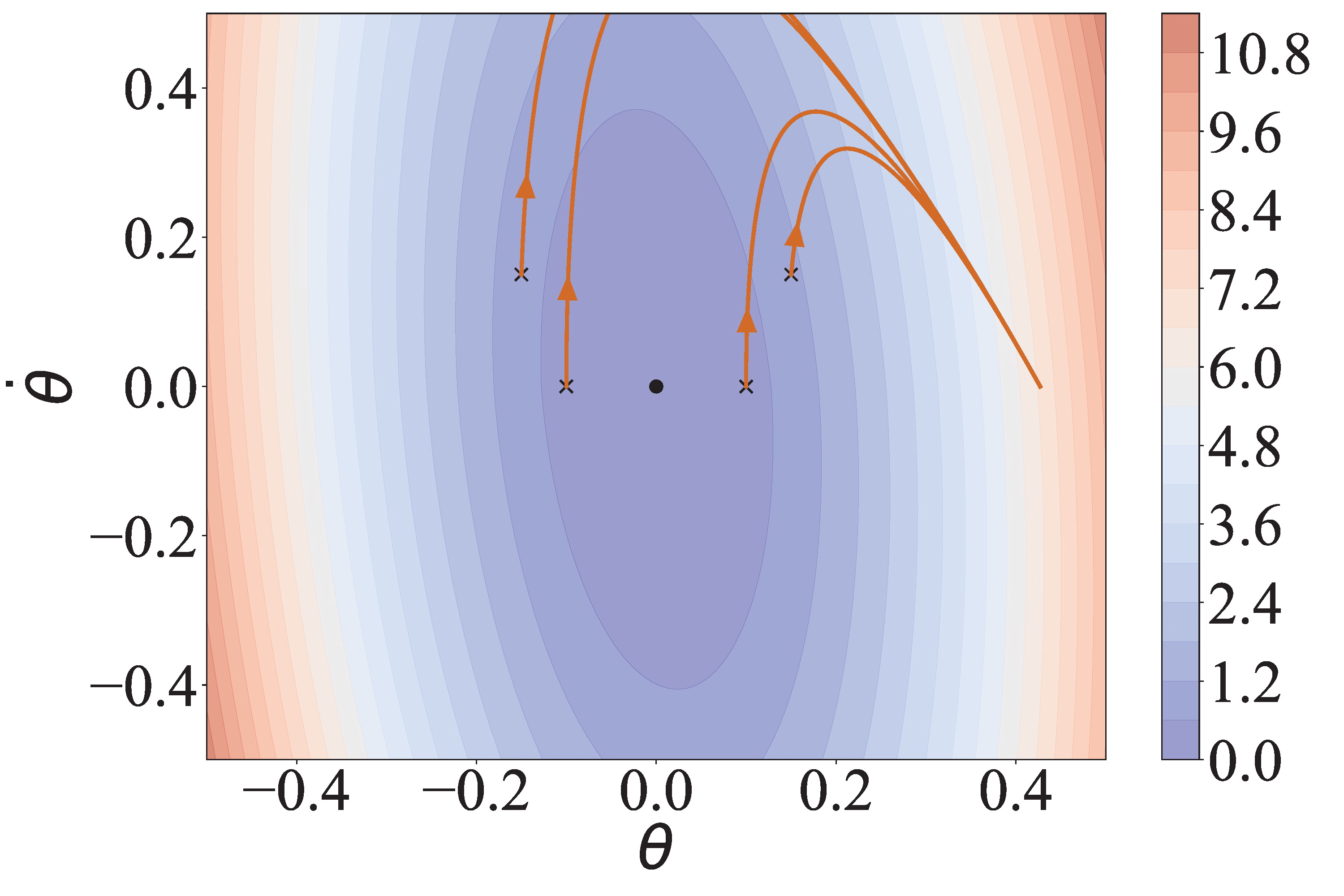
- LYGE can stabilize the system closest to the goal.
- PPO can stabilize the system a bit farther from the goal.
- AIRL, D-REX, and SSRR stabilize the system farther from the goal.
CartIIPole Environment:
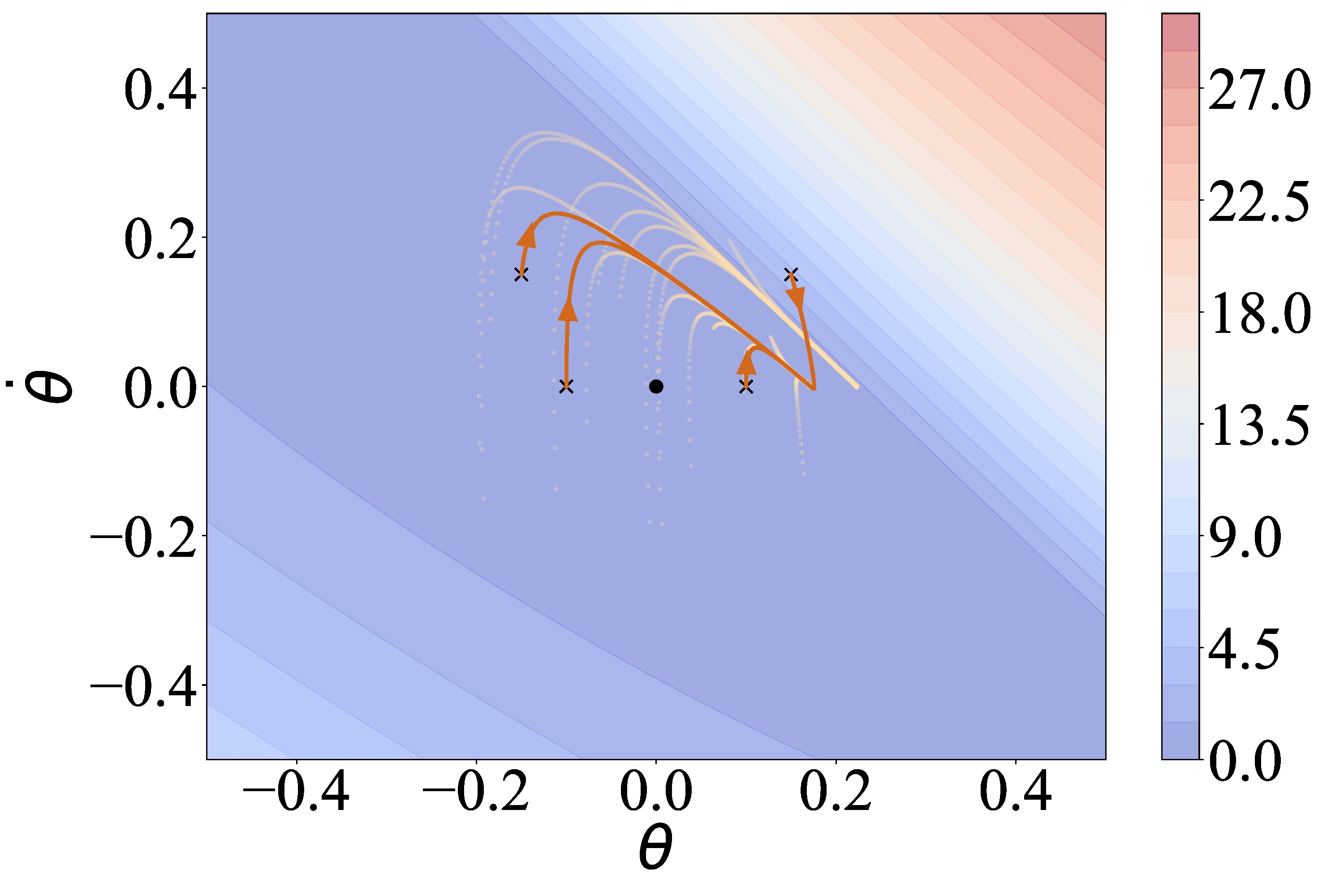
- LYGE can stabilize the system.
- PPO can also stabilize the system.
- AIRL recovers the bad behavior of the demonstrations.
- D-REX stabilizes the system at the wrong state.
- SSRR cannot stabilize the system.
F-16GCA Environment:
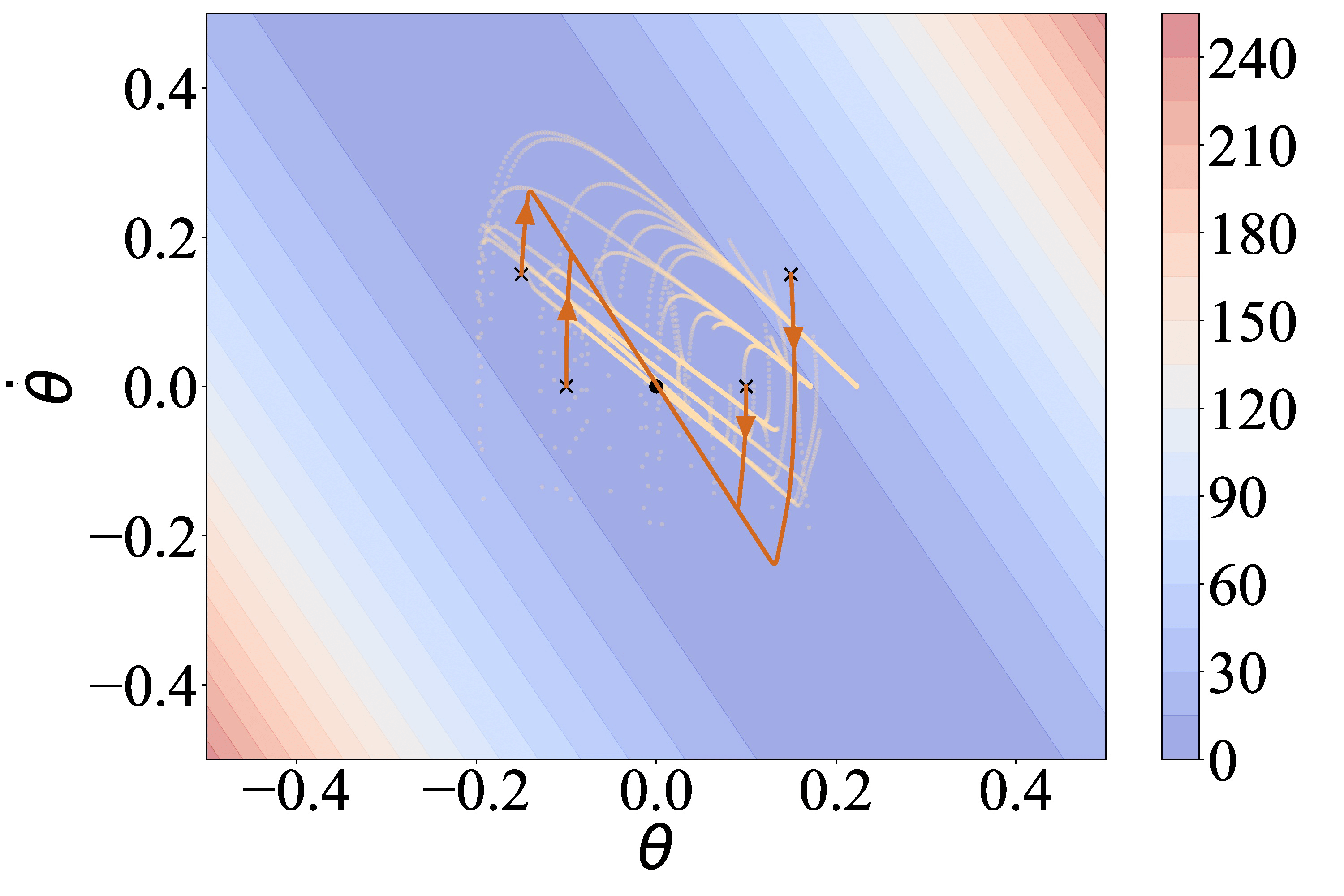
- LYGE pulls up F-16 fast and stabilizes it at the desired altitude.
- PPO makes dangerous behaviors, and sometimes collides with the ground.
- AIRL and D-REX sometimes collide with the ground.
- SSRR also makes dangerous behaviors.
F-16Tracking Environment:
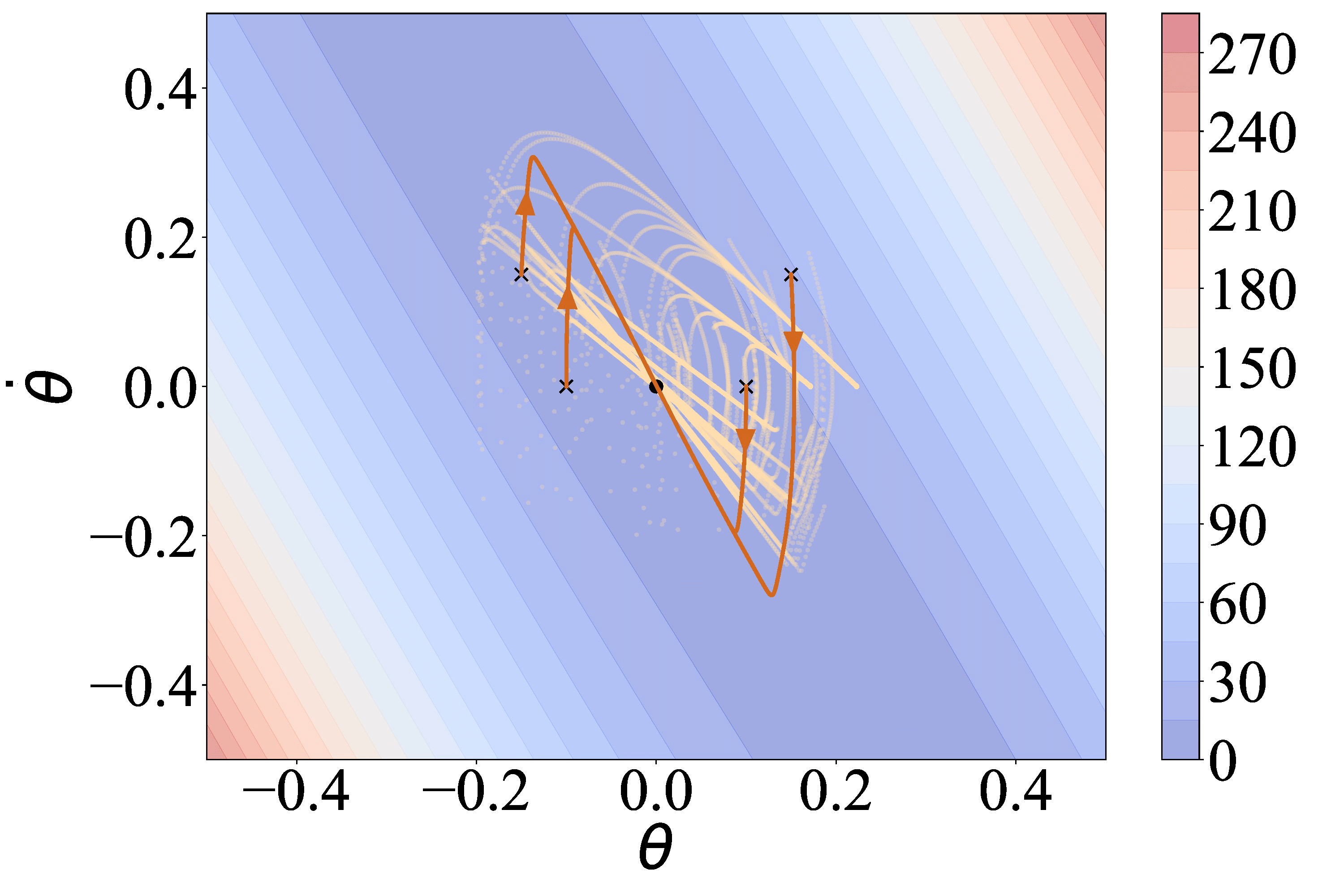
- LYGE tracks the goal point well.
- PPO and SSRR make the F-16 spins, which is a dangerous behavior.
- AIRL and D-REX cannot reach the goal.