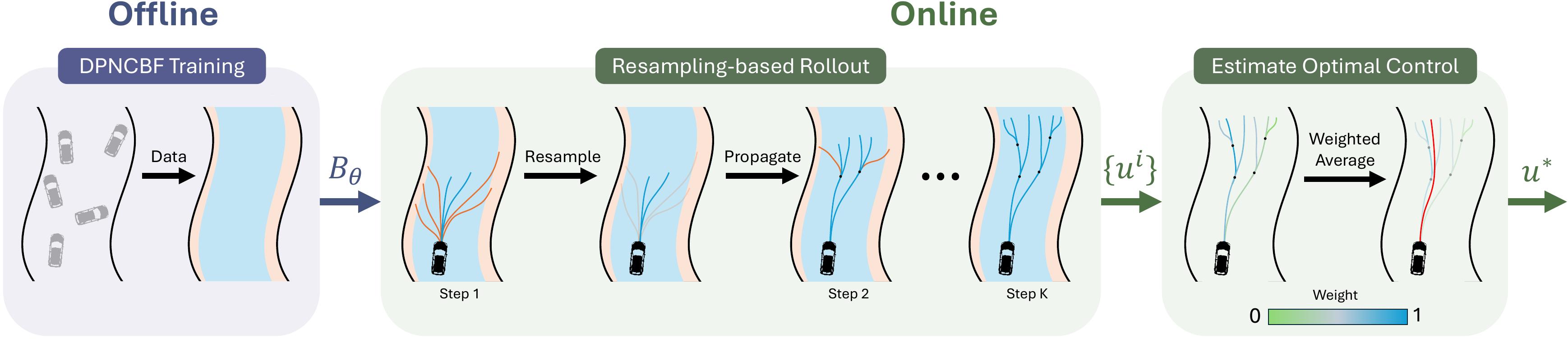
Resampling-based Rollouts (RBR)
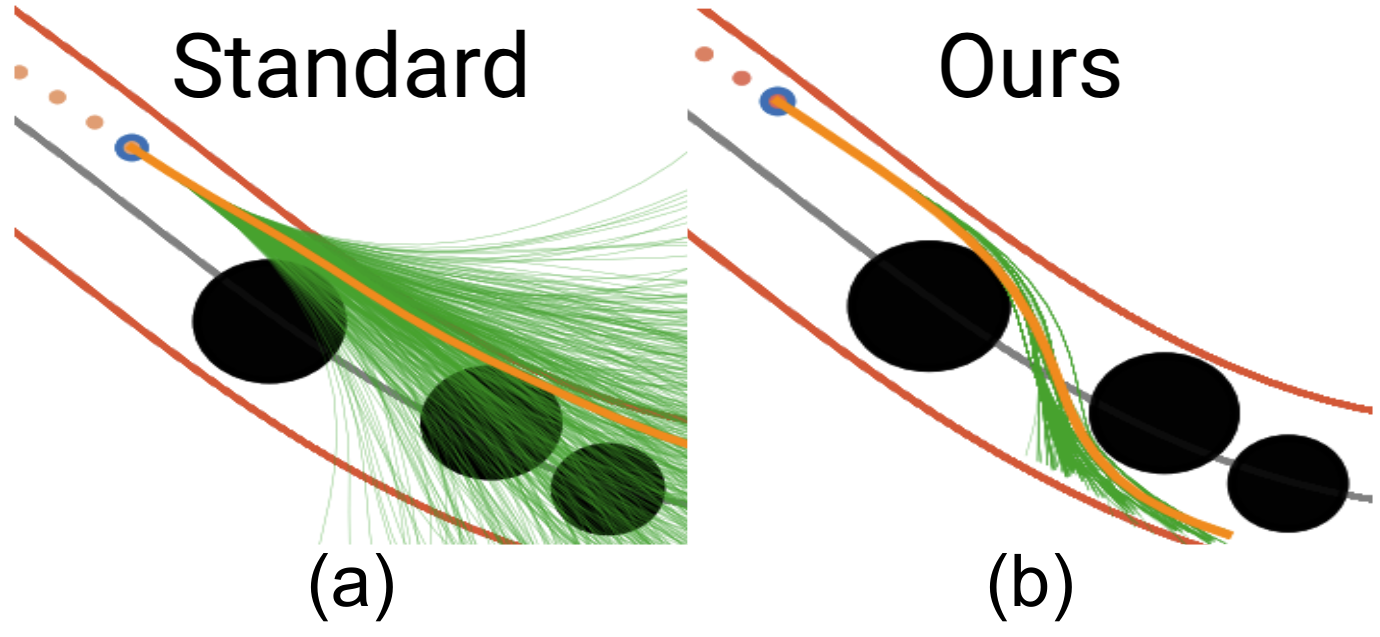
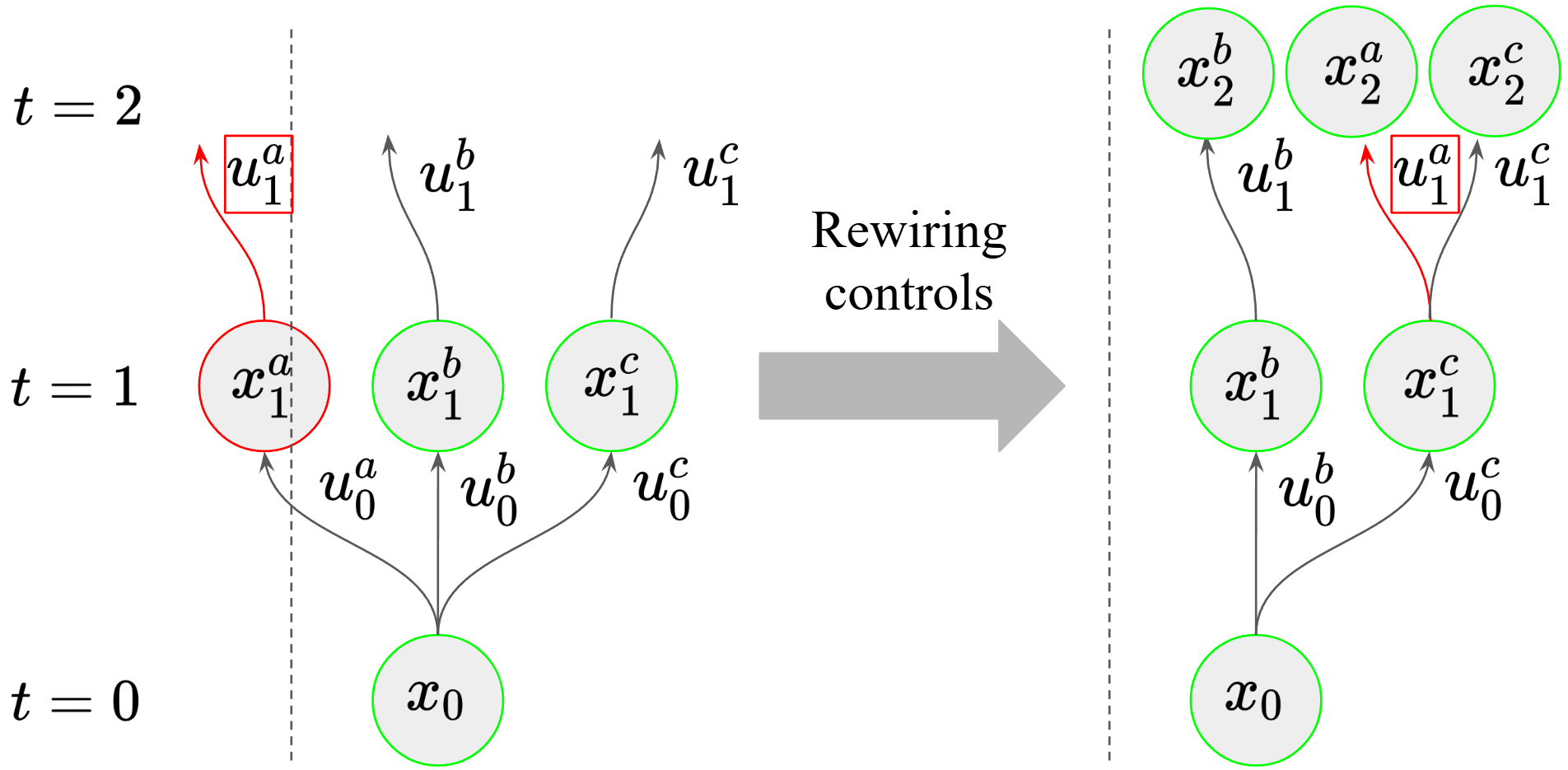
We propose a new rollout strategy, resampling-based rollouts (RBR) that more efficiently concentrates samples away from the unsafe region. Inspired by particle-filters, we resample particles that have violated any safety constraints among the set of particle that are still safe during the rollout process.
Discrete Policy Neural CBFs
We extend previous work on learning neural CBFs to the discrete-time setting. Notably, we use the fact that policy-conditioned value function for the discrete-time avoid problem is a discrete-time CBF for any policy.
Simulation Experiments
AutoRally
MPPI
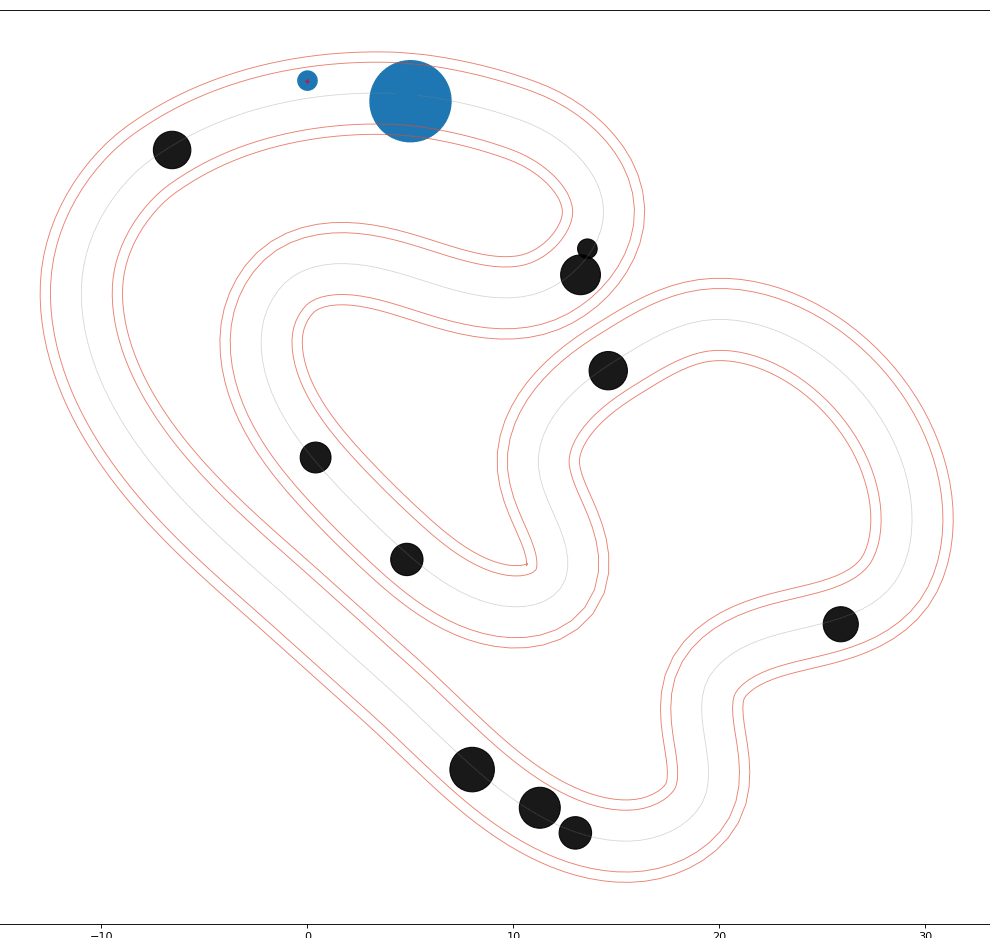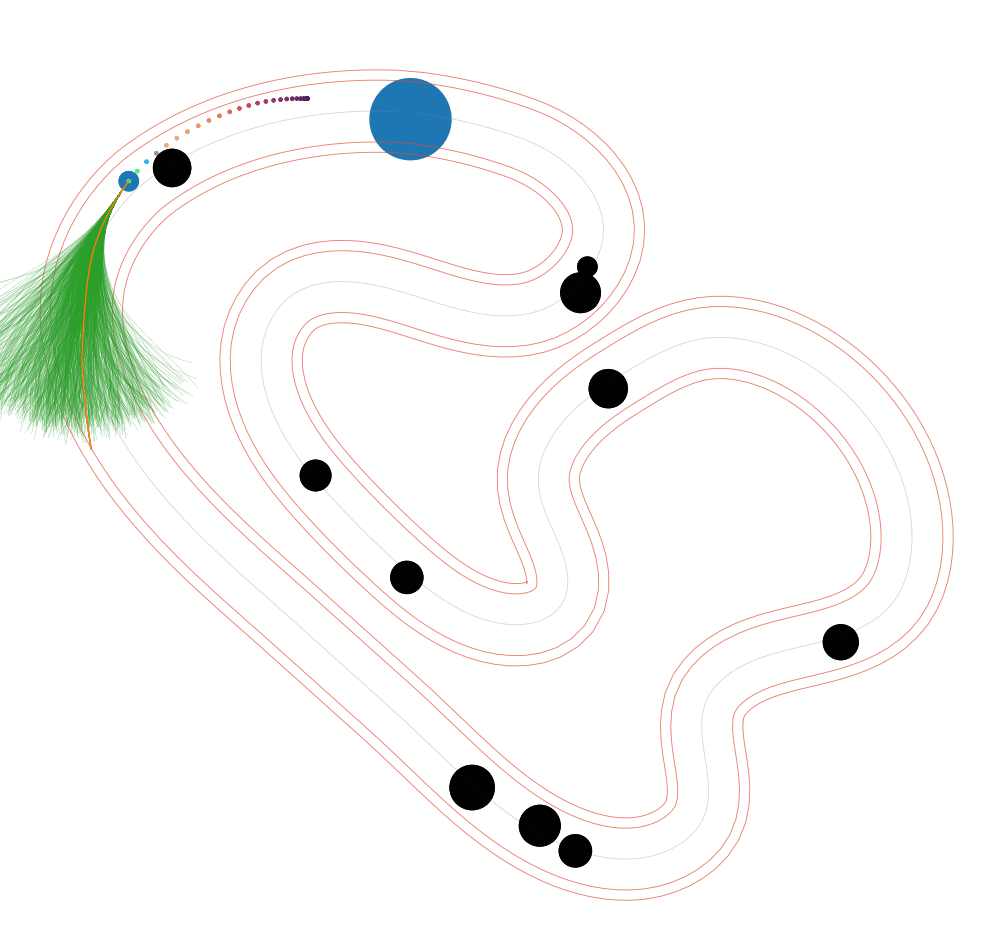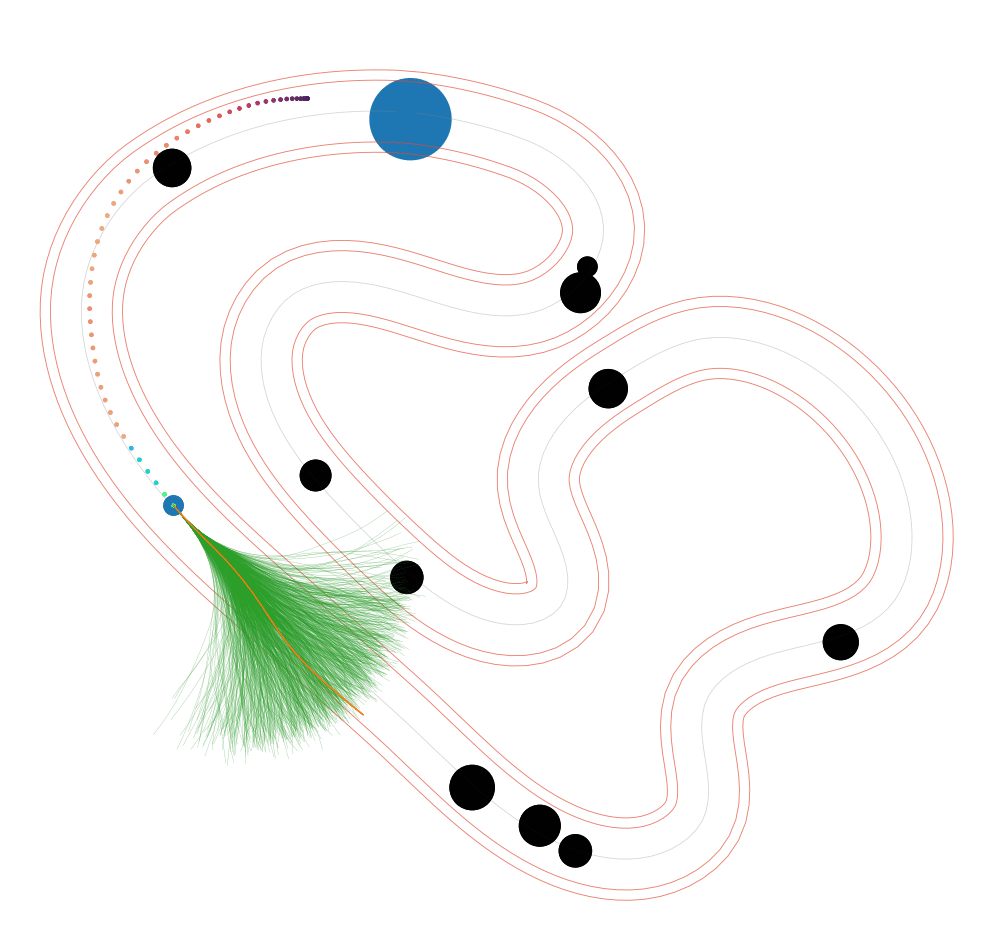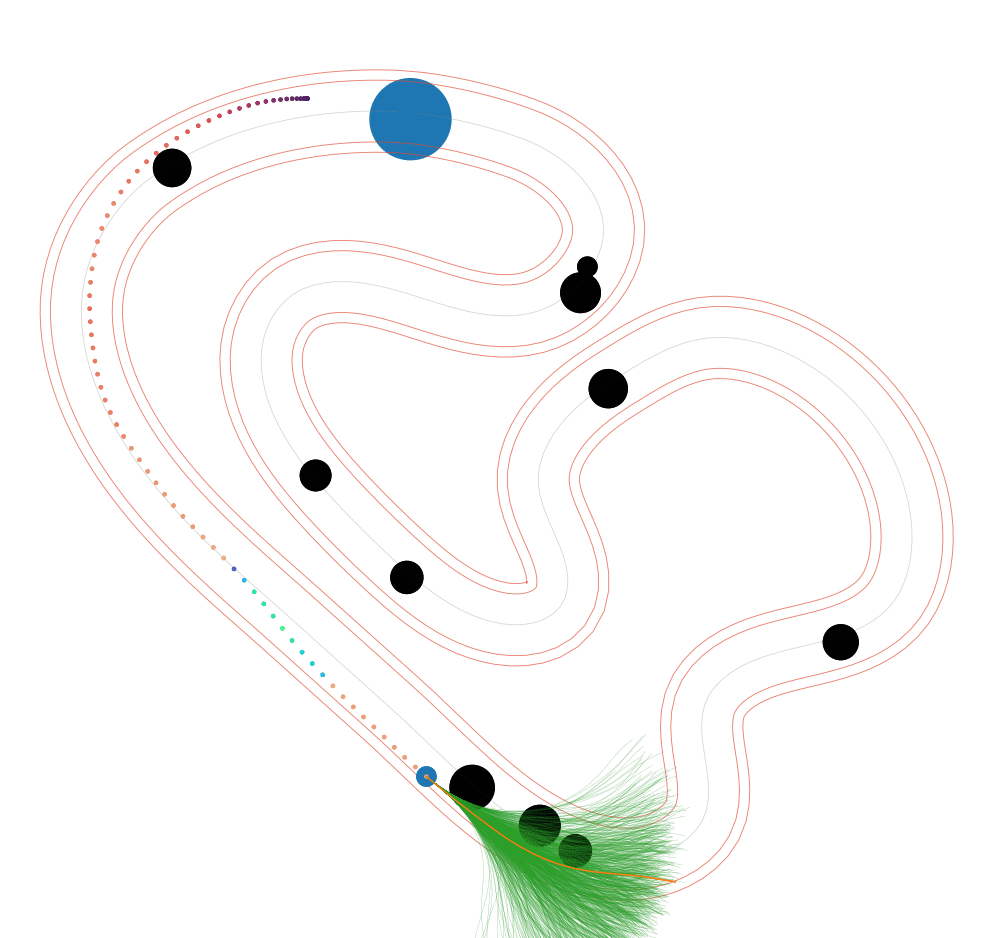
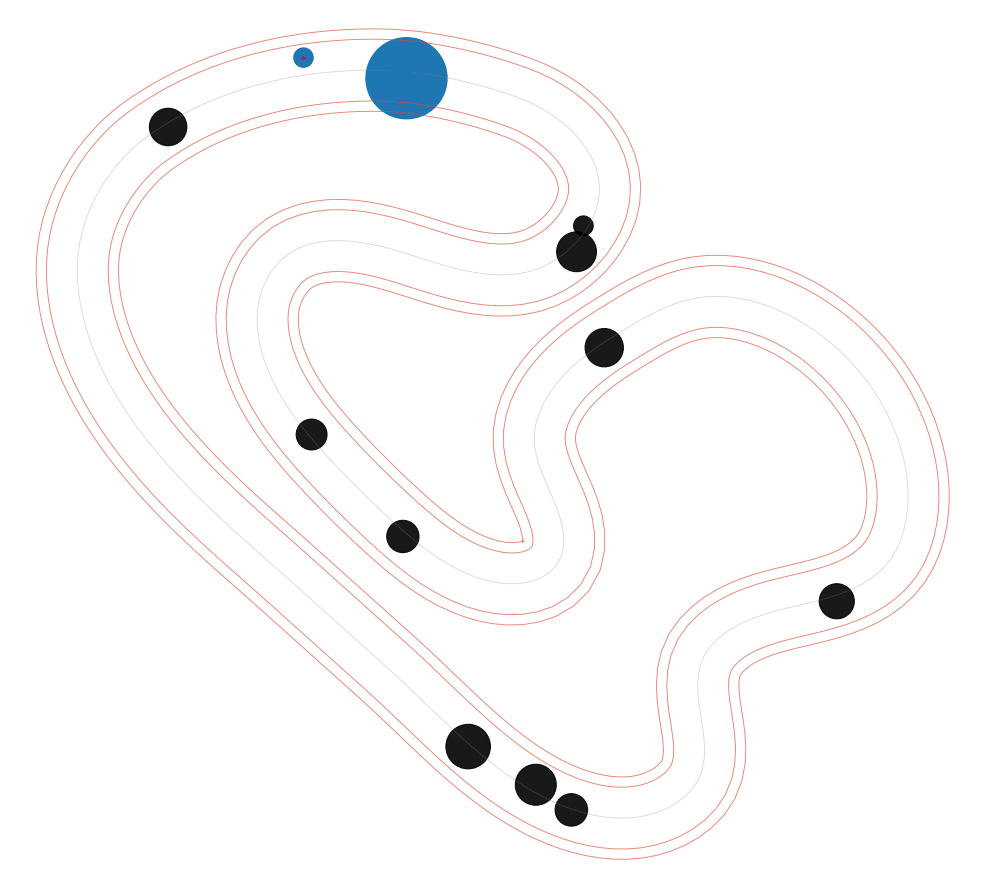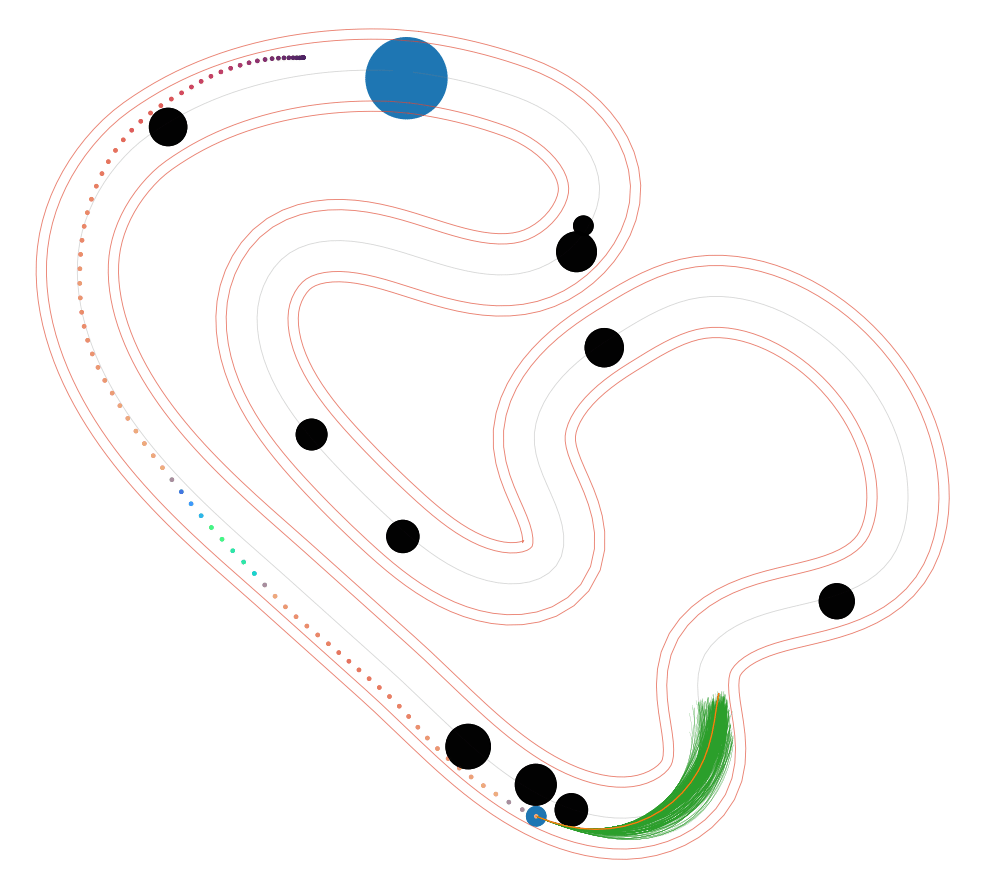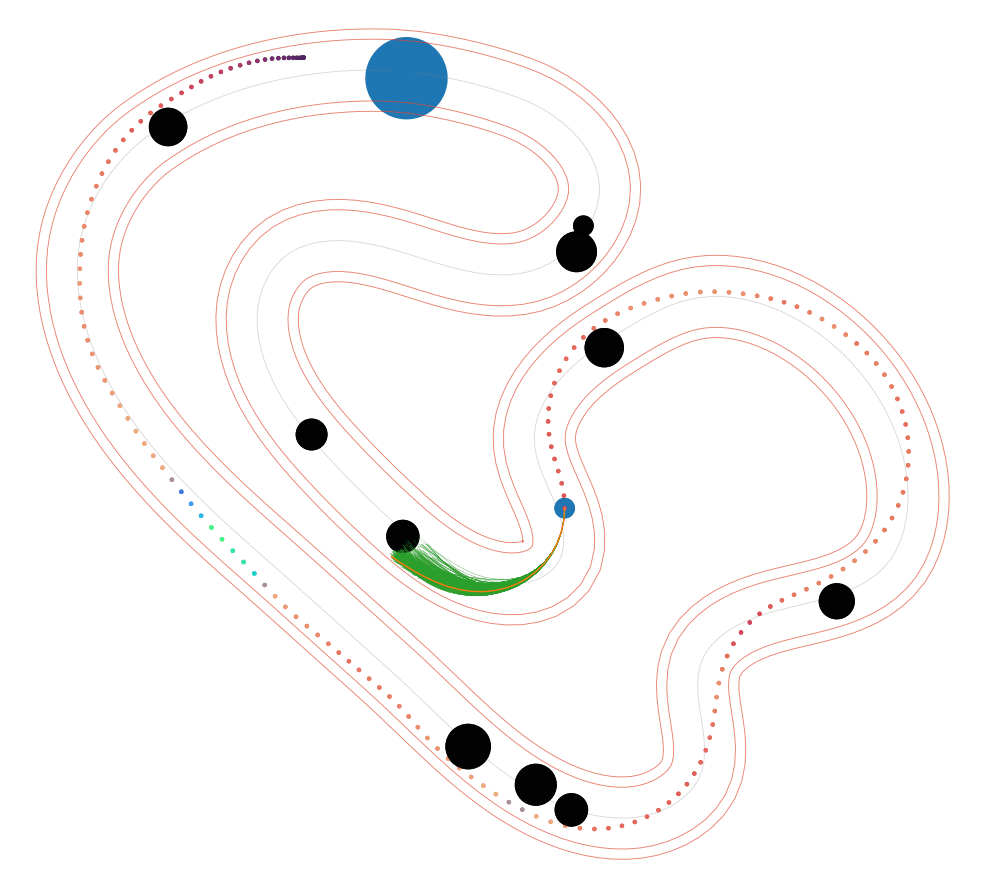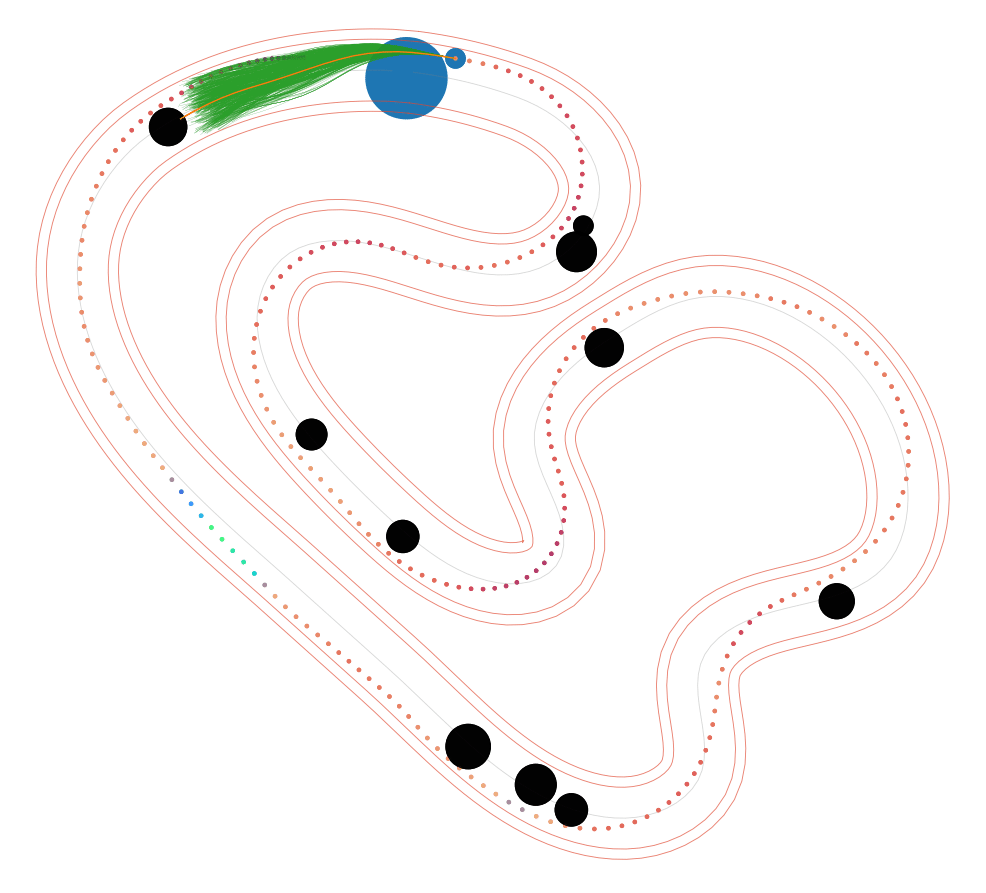
NS-MPPI (Ours)
Drone
Shield MPPI

NS-MPPI (Ours)

AutoRally Hardware Experiments
Abstract
A common problem when using model predictive control (MPC) in practice is the satisfaction of safety specifications beyond the prediction horizon. While theoretical works have shown that safety can be guaranteed by enforcing a suitable terminal set constraint or a sufficiently long prediction horizon, these techniques are difficult to apply and thus are rarely used by practitioners, especially in the case of general nonlinear dynamics. To solve this problem, we impose a tradeoff between exact recursive feasibility, computational tractability, and applicability to ''black-box'' dynamics by learning an approximate discrete-time control barrier function and incorporating it into a variational inference MPC (VIMPC), a sampling-based MPC paradigm. To handle the resulting state constraints, we further propose a new sampling strategy that greatly reduces the variance of the estimated optimal control, improving the sample efficiency, and enabling real-time planning on a CPU. The resulting Neural Shield-VIMPC (NS-VIMPC) controller yields substantial safety improvements compared to existing sampling-based MPC controllers, even under badly designed cost functions. We validate our approach in both simulation and real-world hardware experiments.