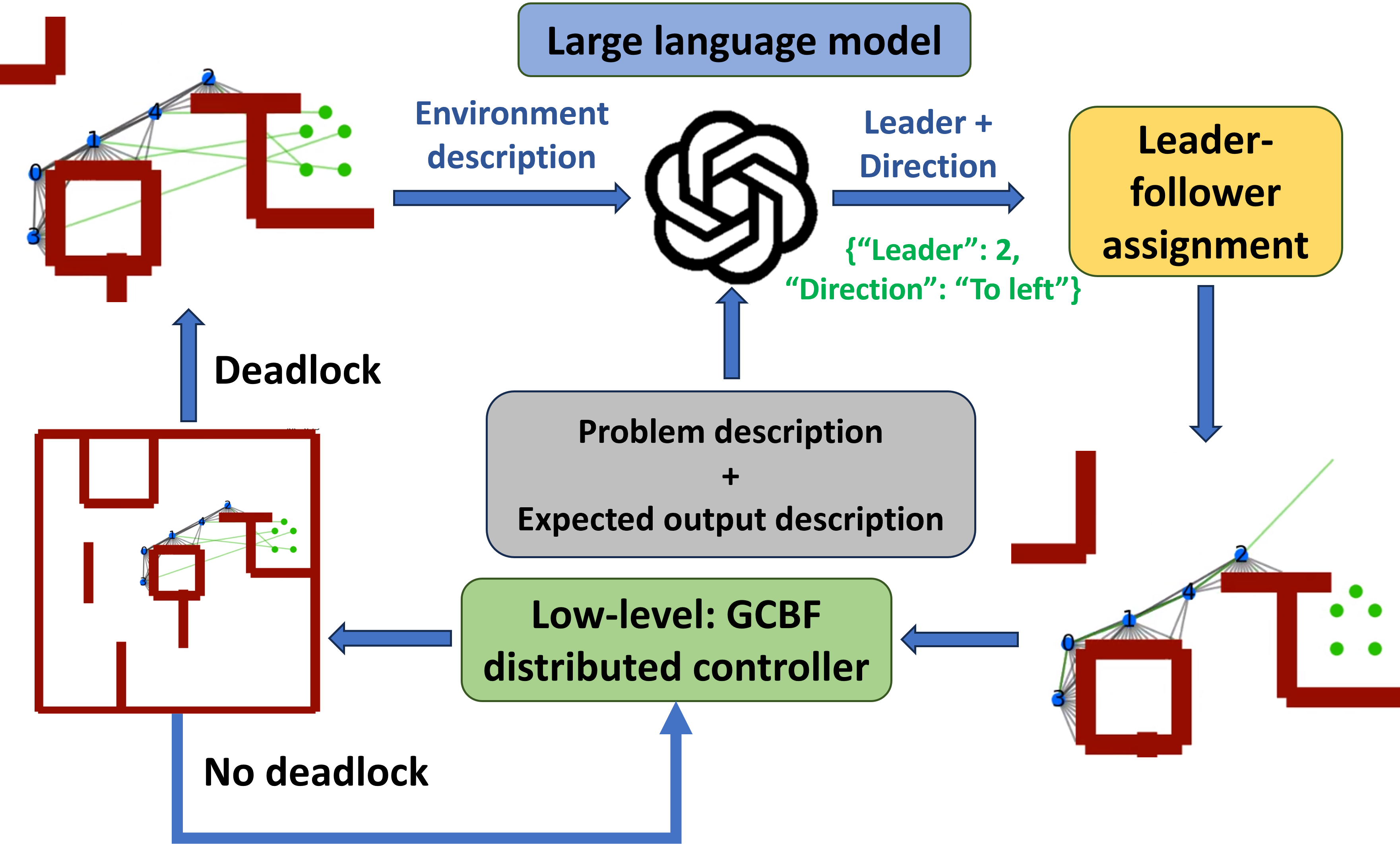
User prompts used for querying LLMs are given below.
- Task description: We are working with a multi-robot system navigating in an obstacle environment to reach their respective goal locations. The objective is to move the robots toward their goal locations while maintaining safety with obstacles, safety with each other, and inter-agent connectivity. Safety is based on agents maintaining a minimum inter-agent "safety radius" while connectivity is based on connected agents remaining within a "connectivity radius". Your role as the helpful assistant to provide a high-level command when the system gets stuck near obstacles. The high-level command is in terms of a leader assignment for the multi-robot system and a direction of motion for the leader. An optimal choice of leader and moving direction minimizes the traveling distance of agents toward their goals and maintains safety and connectivity.
- Environment state: The multi-robot environment description consists of the tuple: (Number of agents, Safety radius, Connectivity radius, Agent locations, Agent goals, Locations of visible obstacles) The environment consists of robot Agents with information ("AgentId"=id, "current state"=(x,y), "goal location"=(xg,yg), "obstacle seen at"=[(xo, yo)]). In addition, there are global environment variables "Number of agents" = N, "Safety radius" = r, "Connectivity radius" = R.
- Desired output: The expected output is a JSON format file with the keys "Leader" and "Direction". The key "Leader" can take integer values in the range (1, Number of agents) and "Direction" in the range ("To goal", "To left", "To right"). If there is an obstacle in between the leader location and its goal location, then the "Direction" should be "To left" or "To right" based on whether it is able to freely move to the left or right of the obstacle. If there is no obstacle in leader's way to its goal location, then the "Direction" should be "To goal".
-
Example Scenario
An example environment description is as follows.
***Name***Env:485***Number of agents***5***Safety radius***0.05***Connectivity radius***0.5***Agents
***AgentId***1***current state***(3.17,2.97)***goal location***(3.69,3.69)***obstacles seen at***[(3.25,2.97),(3.25,2.95),(3.25,2.99)]
***AgentId***2***current state***(3.05,2.13)***goal location***(3.97,3.97)***obstacles seen at***[(3.25,2.21),(3.25,2.26),(3.32,2.18)]
***AgentId***3***current state***(3.04,2.57)***goal location***(3.69,3.69)***obstacles seen at***[(3.25,2.57),(3.25,2.61),(3.25,2.53)]
***AgentId***4***current state***(3.03,2.34)***goal location***(3.97,3.97)***obstacles seen at***[(3.25,2.34),(3.25,2.39),(3.25,2.30)]
***AgentId***5***current state***(3.09,2.78)***goal location***(3.83,3.83)***obstacles seen at***[(3.25,2.78),(3.25,2.75),(3.25,2.81)]
For the given example, an acceptable output is {"Leader": 3, "Direction": "To goal"}. An unacceptable output is {"Leader": 0, "Direction": "To goal"} since the leader should be in the range (1, 5). An unacceptable output is {"Leader": 7, "Direction": "To goal"} since the leader should be in the range (1, 5).